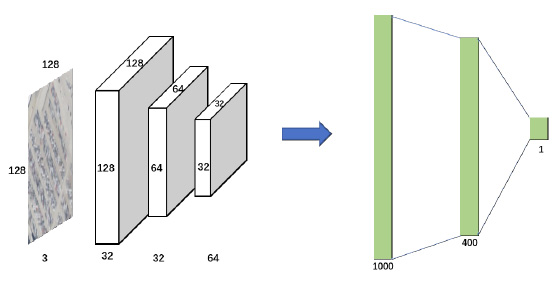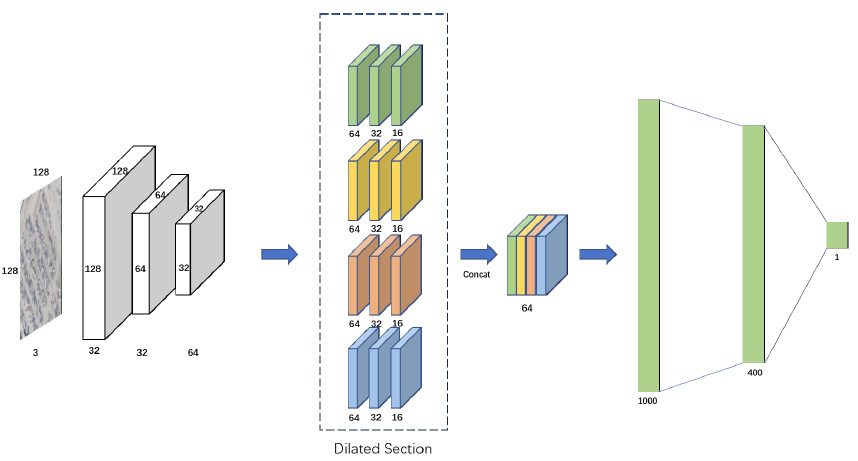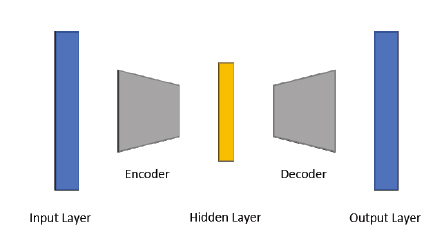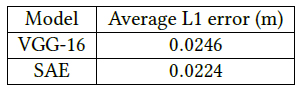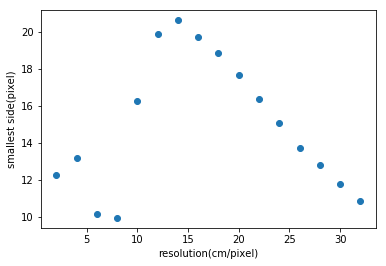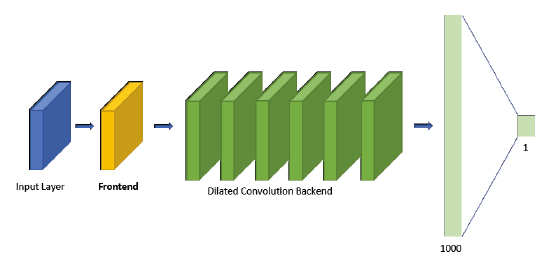
Deep learning regression model for estimating the spatial resolution of an overhead image.
The input is an image and the output is the estimated resolution in meters per pixel.
We experimented with different frontends including a standard pretrained CNN and an SAE encoder.

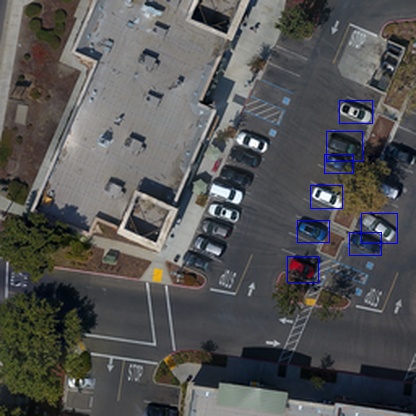
Sample images from our dataset for training and evaluating our bottom-up approach to estimating the spatial resolution.
Columns from left to right depict parking lot, vegetation, housing, and road regions.
Top row: 0.15 meter/pixel images
Second row: 0.30 meter/pixel images
Third row: 0.6 meter/pixel images
Bottom row: 1.0 meter/pixel images.